
Softwarearchitektur verfolgt im wesentlichen zwei Ziele: die Strukturierung von Softwaresystemen und die Minimierung von Abhängigkeiten zwischen den Strukturkomponenten, den sogenannten Bausteinen. Spätestens seit den Neunzigerjahren war das Multi-Tier-Pattern, die klassische Schichtenarchitektur, der Stand der Kunst. Seit einigen Jahren wird dieses Grundmuster zunehmend durch einen neuen De-facto-Standard abgelöst, der als Hexagonale Architektur bekannt geworden ist. Was hat es mit diesem mystischem Begriff auf sich, und welche Vorteile bringt dieser Architekturstil für die Softwareentwicklung?
Im ersten Teil dieser Artikelserie geht es darum, die Begriffe zu klären und den prinzipiellen Aufbau einer Hexagonalen Architektur zu verstehen. Doch zunächst machen wir einen kleinen Ausflug in die Entstehungsgeschichte dieses populären Mikroarchitekturmusters.
Historische Entwicklung
Alistair Cockburn, 2005
Der Begriff der Hexagonalen Architektur wurde im Jahre 2005 von Alistair Cockburn geprägt, einem der Mitzeichner des Agilen Manifests. Das Wort „hexagonal“ beschreibt dabei lediglich die von Cockburn gewählte grafische Darstellung der von ihm vorgeschlagenen Mikroarchitektur:
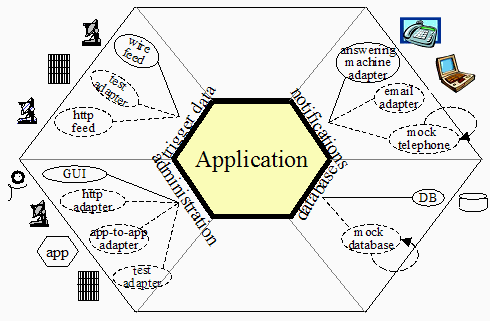
Cockburns Ansatz sieht die strikte Trennung von innerem Code und äußerem Code vor, wobei innen den Anwendungskern meint, also den Teil des Codes, der die Geschäftslogik enthält. Um diesen Kern herum, also außen, sind die technischen Codeteile angeordnet, welche den Geschäftskern mit der äußeren Welt verbinden. Die Außenwelt, das sind beispielsweise Browser-UIs, Mobile-Apps, Mail-Clients, Datenbanken, Message-Broker usw., worüber die Anwendung mit Benutzern oder anderen Systemen Informationen austauscht.
Jeffrey Palermo, 2008
Kurze Zeit später veröffentlichte Jeffrey Palermo seinen Vorschlag zur Strukturierung von Softwaresystemen, den er Onion Architecture nannte. Als Darstellung wählte er konzentrische Kreise, ähnlich den Schichten einer Zwiebel:

Palermo trennt ebenfalls technischen von fachlichem Code, wobei der Applikationskern explizit weiter unterteilt wird: das Object Model fungiert als Zentrum, um das herum sich die Object Services und Application Services anordnen. Die Object-Service-Schicht definiert dabei die technischen Interfaces, die vom äußeren Infrastructure-Layer implementiert werden. Hier begegnet uns das Dependency Inversion Principle (DIP).
Mike Evans, 2004
Viele Grundlagen der modernen Softwareentwicklung wurden bereits 2004 von Eric Evans dargelegt bzw. bestätigt. Sein Buch Domain Driven Design beschreibt eine an fachlichen Gesichtspunkten ausgerichtete Methode, die einen gewissen inneren Aufbau der entwickelten Bausteine impliziert. Das Ziel ist auch hier, fachlichen von technischem Code zu trennen.
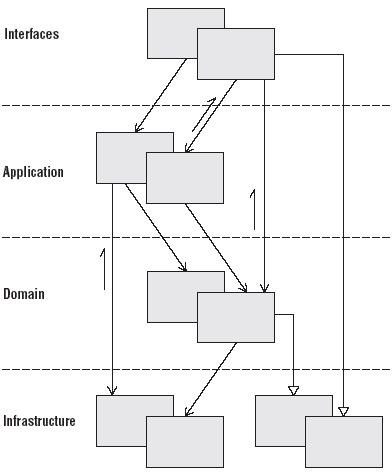
Evans schlägt eine Aufteilung nach Schichten mit strikten Verantwortlichkeiten und definierten Abhängigkeiten vor, wobei der Domain-Layer die zentrale Geschäftskomponente darstellt. Dieser Domain Core hat selbst keine direkten Abhängigkeiten zu anderen Komponenten. Auch hier wieder DIP: der Domain Core definiert die Interfaces, die vom Infrastructure-Layer implementiert werden.
Die Ansätze aller drei Autoren sind sich in ihrem Wesen ähnlich. Zusammengenommen definieren sie eine moderne Mikroarchitektur, die sowohl für den althergebrachten Monolithen als auch bei modernen Microservices anwendbar ist.
Begriffsverwirrung — Hexagonal? Domain Driven? Onion?
Die Namen Hexagonale Architektur, Zwiebel-Architektur und Domain Driven Design (kurz DDD) werden im Alltagsgebrauch oft synonym verwendet. Die Bezeichnung Hexagonal hat sich jedoch durchgesetzt, um dieses Architekturmuster zu beschreiben. Zum einen vermutlich, weil es so schön esoterisch klingt, ohne jedoch Küchenassoziationen zu wecken. Zum anderen ist DDD in seiner Gesamtheit mehr als erkenntnisphilosophische Methodik zu verstehen, ist daher viel breiter gefasst und geht über die reine Strukturierung von Software-Bausteinen hinaus.
Hexagonale Architektur: Definition der Begriffe
Ports
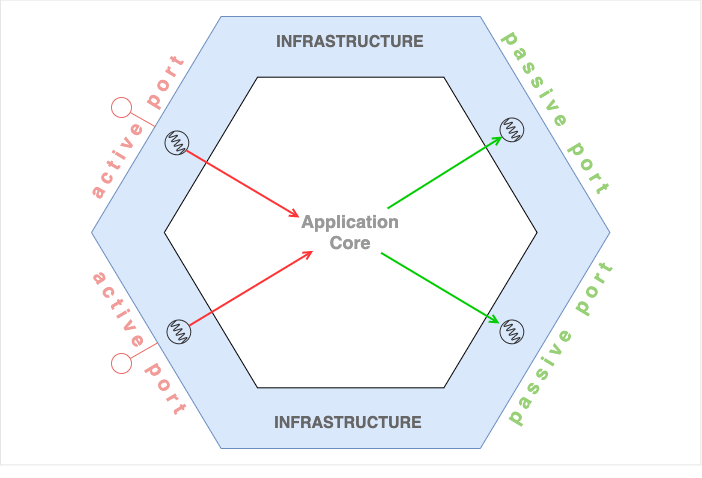
Ein Port definiert logisch zusammengehörige Use Cases und die dafür benötigten Schnittstellen.
In der folgenden Abbildung sind beispielsweise diese Schnittstellen definiert (Beispiele übernommen von Cockburn, s.o.):
- Datenverarbeitung
- Administration
- Events/Notifications (nach außen)
- Datenbankabfragen.
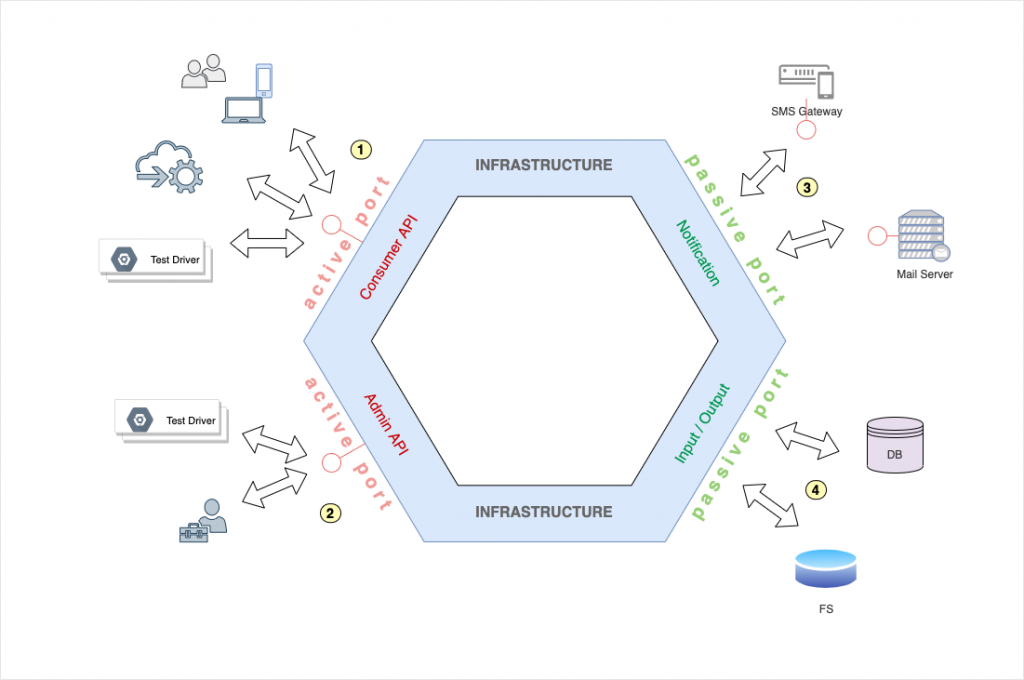
Auf der linken Seite des Hexagons sehen wir die aktiven Ports (1) und (2), während (3) und (4) auf der rechten Seite als passive Ports angeordnet sind. Aktive und passive Ports bilden zusammen den Infrastructure Layer, also den Teil der Anwendung, der mit der Außenwelt kommuniziert.
Aktive und passive Ports
Über die aktiven Ports, die nach außen sichtbar sind, werden Änderungen in der Applikation angestoßen. Menschliche Benutzer oder technische Clients greifen über die öffentlichen Schnittstellen aktiv in den Zustand der Anwendung ein. Aktive Ports werden auch als Primärports oder Inbound Ports bezeichnet.
Dahingegen sind die passiven Ports nicht von außerhalb der Anwendung zugänglich. Über sie kann nur die Anwendung selbst auf andere Systeme lesend oder schreibend zugreifen und die erhaltenen Antworten innerhalb ihrer eigenen Geschäftsprozesse verarbeiten. Die Verwendung dieser Ports erfolgt somit passiv. Über die passiven Ports kann keine direkte Interaktion mit der Anwendung erfolgen. Passive Ports sind auch als Sekundärports oder Outbound Ports bekannt.
Port = Schnittstelle + Datentransport
Die Ports einer Softwareanwendung bestehen aus einer Schnittstellenspezifikation und dem technischen Teil der Implementierung, der Datenstrukturen in die Anwendung hinein und hinaus transportiert.
ISP – Interface Segregation Principle
Passive Ports bilden nicht die komplette Schnittstelle des externen Systems ab, sondern nur genau den Teil, der von der Applikation gerade benötigt wird. So würde der Notification-Port (Nr. 3 in der obigen Abbildung) lediglich den Teil der Mailserver-API nutzen, der zum Versenden von E‑Mails benötigt wird. Das zugehörige DTO enthält dann auch nur die Attribute, die tatsächlich für den Mailversand relevant sind. Werden beispielsweise die Felder CC und BCC nicht benötigt, wird das DTO sie nicht enthalten.
Adapters
Adapter fungieren als Vermittler zwischen Systemen mit unterschiedlichen Schnittstellen.
In der abstrakten Welt der Softwaretechnik dienen Adapter dazu, Datenstrukturen aus Fremdsystemen in das eigene System zu überführen, zu adaptieren, und zwischen beiden Domänen hin- und her zu transformieren.
Primäre und sekundäre Adapter
Zu einem Port gibt es einen oder mehrere Adapter. Aktive Ports enthalten primäre Adapter, das sind die Controller der Anwendung. Über sie gelangen Anweisungen und Daten von außen zum Anwendungskern, um dort die Geschäftslogik auszuführen und Antworten zu erhalten.
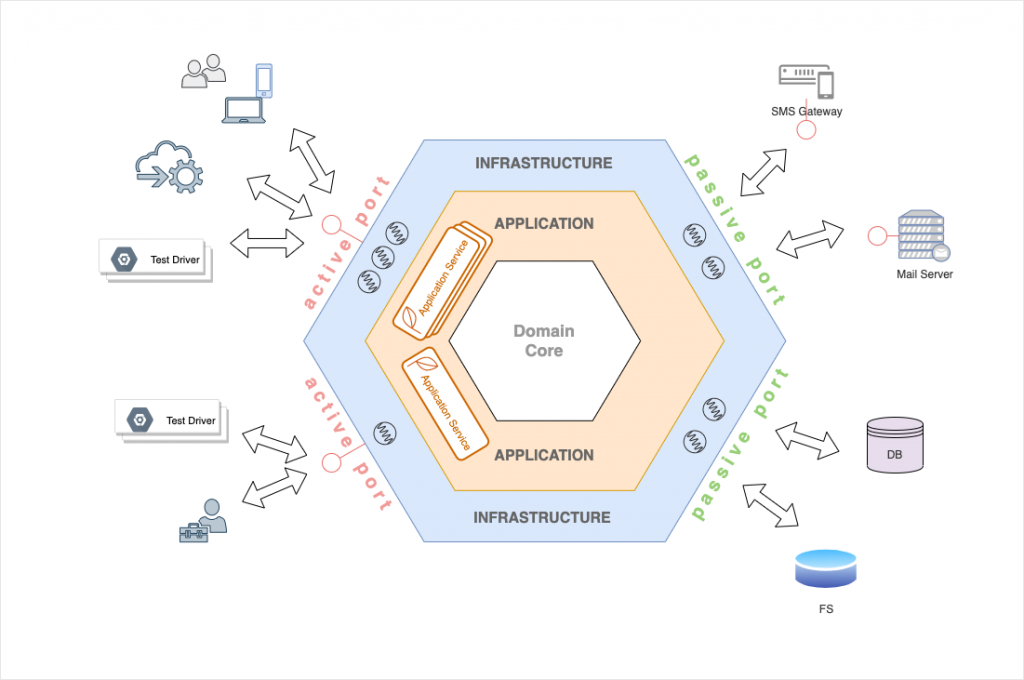
Die sekundären Adapter der passiven Ports werden vom Anwendungskern genutzt, um externe Systeme einzubinden. Beispielsweise andere Microservices, Messaging- oder Storagesysteme, wie die folgenden Grafik veranschaulicht. Sekundäradapter implementieren immer genau den Teil der externen Schnittstelle, der vom Anwendungskern benötigt wird – auch hier wieder ISP.
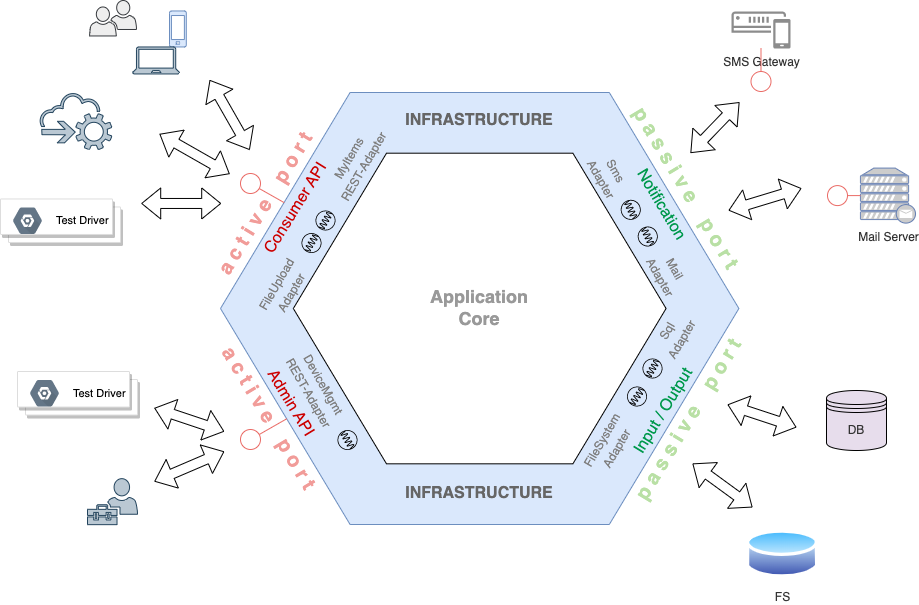
Zu beachten ist hierbei die Richtung der Abhängigkeiten: Primäre Adapter rufen den Anwendungskern, dieser kennt jedoch die primären Adapter nicht. Sekundäre Adapter werden vom Anwendungskern benutzt, kennen diesen jedoch nicht. Die Aufrufhierarchie im Hexagon geht also von links nach rechts, wie folgendes Bild veranschaulicht:
Application
Der Application-Ring im Hexagon markiert die Verbindungsschicht zwischen der Infrastruktur und dem Domainkern. Hier residiert die Applikationslogik. Das ist der Teil der Logik, der nicht die Geschäftsregeln beinhaltet, wohl aber die Use Cases anstößt und koordiniert. Außerdem sind hier die technischen Belange der Applikation abgebildet, beispielsweise Security, Logging, Datenbanktransaktionen oder Sessionhandling. Bei der vielzitierten Trennung von Technik und Fachlichkeit kommt dem Applicationlayer eine entscheidende Bedeutung zu. Es sind in erster Linie die Application Services, die seine Substanz bilden.
Application Service
Application Services definieren die Einstiegspunkte für Use Cases und koordinieren deren Abläufe.
Ein Application Service wird von einem Primäradapter, beispielsweise einem REST-Adapter oder Message-Consumer, aufgerufen. Der Application Service gibt den Aufruf an den Domain Core weiter und stößt dadurch den zugehörigen Use Case an. Zusammenhängende Use Cases werden vom Application Service koordiniert, einzelne Ergebnisse werden zu Antworten aggregiert und erforderliche Events, z.B. Mailversand oder Notifications für andere Services, werden angetriggert. Wo nötig, kommuniziert der Application Service mit den Sekundäradaptern der passiven Ports, um beispielsweise Entitys aus einem Datenbankrepository oder von einer entfernten REST-API zu laden, die für den Ablauf des Use Cases benötigt werden. Wie bereits erwähnt, enthält der Application Service selbst keine Geschäftslogik.
Domain Core
Der Domain Core ist der fachliche Kern der Applikation. Er enthält die fachliche Implementierung der Use Cases mit der auszuführenden Geschäftslogik. Außerdem die Implementierung der Fachklassen, das sogenannte Domain Model.
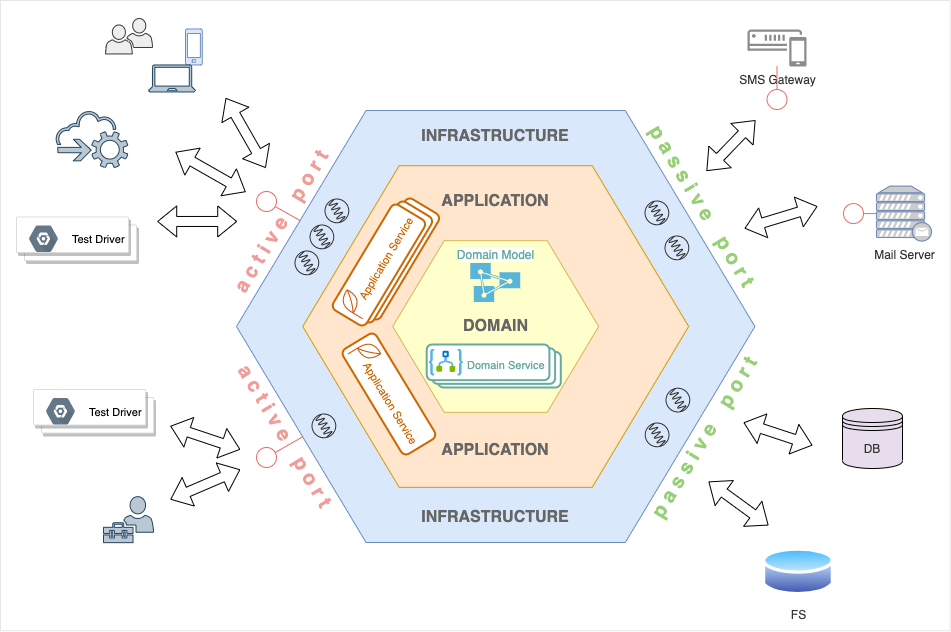
Domain Model
Das Domain Model beinhaltet im Wesentlichen die in dem fachlichen Kontext – Bounded Context im DDD-Jargon – identifizierten Entitäten. Diese bilden den eigentlichen Kern der Applikation. Hier ist das Wissen der Fachdomäne enthalten, soweit es zur Durchführung der abzubildenden Use Cases erforderlich ist. Im Domain Driven Design ist das Domain Model das Herzstück der Software. Application- und Infrastructurelayer werden um den Domainkern herum angeordnet und sind vom diesem abhängig, nicht umgekehrt. Die Darstellung als konzentrisches Hexagon ist dazu geeignet, dieses wichtige Grundprinzip eingängig zu visualisieren. Die Geschäftslogik ist im Rich Domain Model in den Methoden der Fachklassen implementiert. Teile der Logik, die keiner Fachklasse direkt zugeordnet werden können, werden in den Domain Services implementiert.
Domain Services
Die Domain Services enthalten übergreifende Geschäftslogik, die nicht eins-zu-eins auf Fachklassen abgebildet werden kann. Domain Services werden vom Application-Layer, genauer von den dortigen Application Services aufgerufen. Ein Domain Service darf direkten Zugriff auf die Infrastructure haben und deren passive Adapter benutzen. Hierbei ist allerdings abzuwägen, ob der Aufruf besser in den Application Layer zu verlagern wäre.
Im ersten Fall kann der Domain Layer ein IoC-Interface bereitstellen, um den Adapter von der Domain zu entkoppeln.
Im zweiten Fall würde der Application Service mit der Infrastructure kommunizieren und das Ergebnis des Aufrufs in adäquater Form an die Domain übergeben. Diese Variante sollte bevorzugt eingesetzt werden, es sei denn, praktische Gründe sprechen für den anderen Weg.
Ferner ist darauf zu achten, dass keine Infrastructure-Dependencys in die Domain hineingezogen werden, beispielsweise durch Referenzen auf DTOs als Aufrufparameter oder Rückgabewerte eines Adapters. Diese müssen vor der Übergabe zunächst innerhalb der Adapter-Ebene auf Domain-Entitys gemappt werden. Die Mappinglogik fungiert dabei als Anti-Corruption-Layer (ACL) nach DDD, der dafür sorgt, dass das Model des Domain Cores nicht durch fremde Models externer APIs „verschmutzt“ wird.
Abhängigkeiten und Aufrufhierarchien
Das Hexagon besteht aus zwei logischen Hälften, der linken aktiven Seite und der passiven rechten. In der Abbildung ist zu erkennen, dass Aufrufe nur in eine Richtung gehen, und zwar von links nach rechts. Niemals würde ein passiver Adapter einen Application Service aufrufen, oder dieser einen aktiven Adapter. Solche Calls sind strikt verboten.
Die Abhängigkeiten der Schichten gehen immer von außen nach innen. Allerdings gibt es keine Dependency von dem passiven Teil des Infrastructure Layers zum Application Layer.
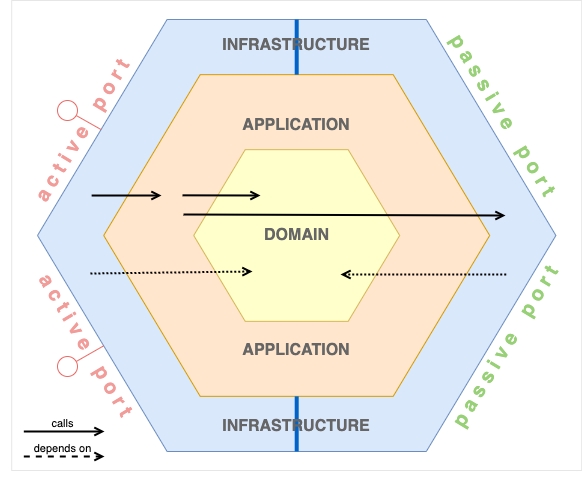
Somit lässt sich zusammenfassen:
- Jeder Baustein kann eine Dependency zum Domain Model haben.
- Die Benutzung der Geschäftslogik bleibt jedoch den Application Services vorbehalten.
- Application Services können sowohl die Sekundäradapter der passiven Ports als auch die Domain Services benutzen.
- Domain Services können Sekundäradapter benutzen, diese können durch IoC entkoppelt werden.
- Das Domain Model hat keinerlei Abhängigkeiten zu anderen Bausteinen.
Ausblick
Im nächsten Teil tauchen wir tiefer in die einzelnen Ringe hinein und definieren deren Inhalte im Detail. Weiterhin müssen wir einigen Fragen nachgehen, die bei der Umsetzung eines Architekturmusters immer wieder gestellt werden. Zum Beispiel, was ist Businesslogik, was ist Anwendungslogik, und worin unterscheiden sie sich? In welchem Teil des Hexagons werden Domainobjekte erzeugt, die sich aus Daten von mehreren Drittsystem zusammensetzen? Wo werden Querschnittsthemen wie Datenvalidierung, Exceptionhandling, Logging usw. implementiert?
Es bleibt also spannend. Bis dahin, happy engineering 🙂
„Patterns are useful because it gives software professionals a common vocabulary with which to communicate. “
Jeffrey Palermo